
The Challenge of Viewpoint Invariance in VLP. We selected benchmarks representing clean distributions (ImageNet-1K, CIFAR-100), common 2D-OOD (ImageNet-V2, ImageNet-R(endition), ImageNet-Sketch), and viewpoint-OOD (ImageNet-V(iewpoint)+, OOD-CV(Pose), MIRO). We display samples from these data distributions and report the Top-1 accuracy of the original CLIP (ViT-L/14) and our improved
![]() OVT-CLIP (ViT-L/14)
OVT-CLIP (ViT-L/14)
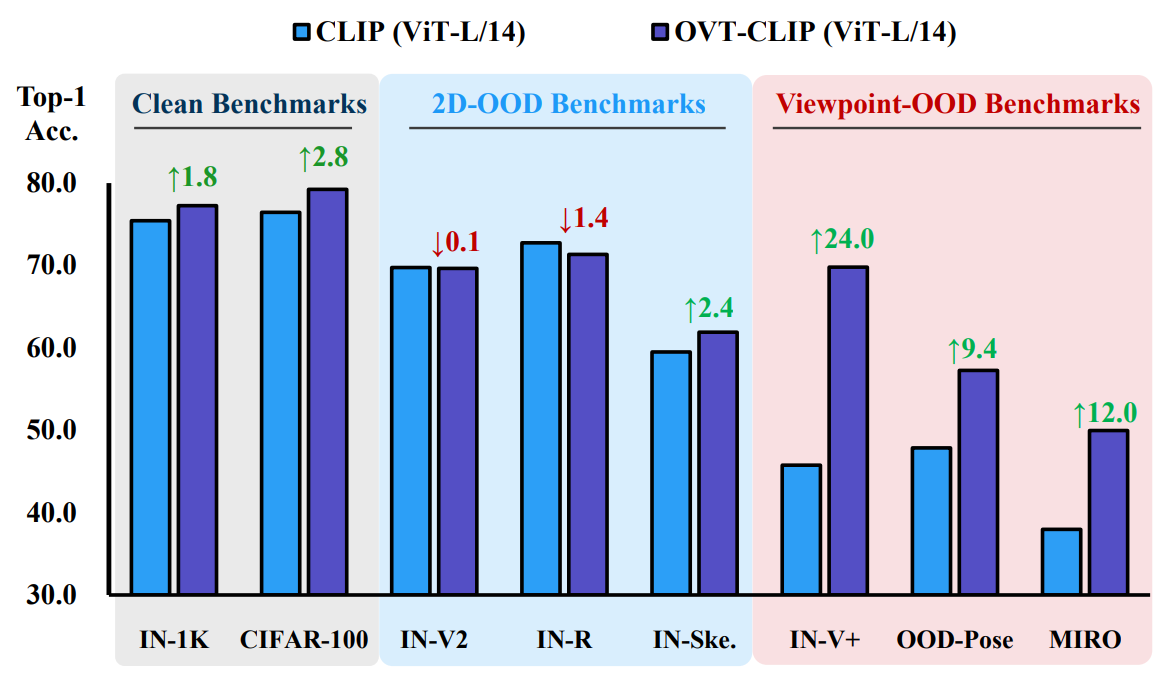
The Challenge of Viewpoint Invariance in VLP. We selected benchmarks representing clean distributions (ImageNet-1K, CIFAR-100), common 2D-OOD (ImageNet-V2, ImageNet-R(endition), ImageNet-Sketch), and viewpoint-OOD (ImageNet-V(iewpoint)+, OOD-CV(Pose), MIRO). We display samples from these data distributions and report the Top-1 accuracy of the original CLIP (ViT-L/14) and our improved
![]() OVT-CLIP (ViT-L/14)
OVT-CLIP (ViT-L/14)
🚀[2024-08-13]: Congratulations to our Omniview-Tuning for being selected for ECCV2024 Oral, see you in Milan!🌟
🔥[2024-07-15]: We released the training code of Omniview-Tuning, and part of the MVCap dataset, feel free to try tuning your viewpoint-robustness VLP models!
Vision-Language Pre-training (VLP) models, such as CLIP and BLIP, have shown great promise in learning transferable representations across various vision tasks. However, a recent study (Ruan et.al, 2023) identifies that although VLP models excel at handling OOD data of 2D images, they suffer significant performance degradation under 3D viewpoint changes, revealing a notable shortcoming of the existing VLP models.
To adress this gap,
we build the Multi-View Caption (MVCap) dataset — a comprehensive
collection of over four million multi-view image-text pairs across more
than 100K objects, providing more potential for VLP models to develop
generalizable viewpoint-invariant representations.
We present ![]() Omniview-Tuning, a novel fine-tuning framework
to enhance the viewpoint invariance of VLP models. In
Omniview-Tuning, a novel fine-tuning framework
to enhance the viewpoint invariance of VLP models. In
![]() Omniview-Tuning,
we introduce a Cross-Viewpoint Alignment objective through a minimax-like optimization strategy, effectively
aligns representations of identical objects from diverse viewpoints without
causing overfitting. Additionally, OVT fine-tunes VLP models in a
parameter-efficient manner, leading to minimal computational cost.
Omniview-Tuning,
we introduce a Cross-Viewpoint Alignment objective through a minimax-like optimization strategy, effectively
aligns representations of identical objects from diverse viewpoints without
causing overfitting. Additionally, OVT fine-tunes VLP models in a
parameter-efficient manner, leading to minimal computational cost.
We conduct extensive experiments to show the efficacy of the OVT framework in improving the viewpoint invariance for VLP models while maintaining performance on clean data and 2D-OOD samples. For example, by fine-tuning CLIP with OVT on different architectures (ViT-B/32, ViT-B/16, and ViT-L/14), the Top-1 accuracy on viewpoint-OOD benchmarks increased by an average of 9.6%, 10.2%, and 8.9%, respectively, with only a minimal sacrifice on 2D-OOD benchmarks by an average of 2.6%, 1.4%, and 0.2%. Furthermore, serving as the visual encoder in VLLMs (e.g., LLaVa), OVT-CLIP also effectively improves viewpoint invariance in image captioning and visual question answering tasks.
We introduce a large-scale Multi-View Caption (MVCap) dataset tailored for viewpoint invariance of VLP models, comprising over 4.6 million multi-view image-text pairs across >100K objects. To assemble a diverse collection of multi-view imagetext pairs, we amalgamate various 3D assets with real-world multi-view data. This process involves an extensive selection and rendering of multi-view images from existing datasets. We then utilize a Vision Large Language Model (VLLM) for automated caption generation to obtain semantically rich textual descriptions without extensive manual efforts. To ensure category consistency across varying viewpoints in the generated captions, we implement a category-guided prompting strategy, which maintains accuracy in textual descriptions for different viewpoints of the same object or scene.
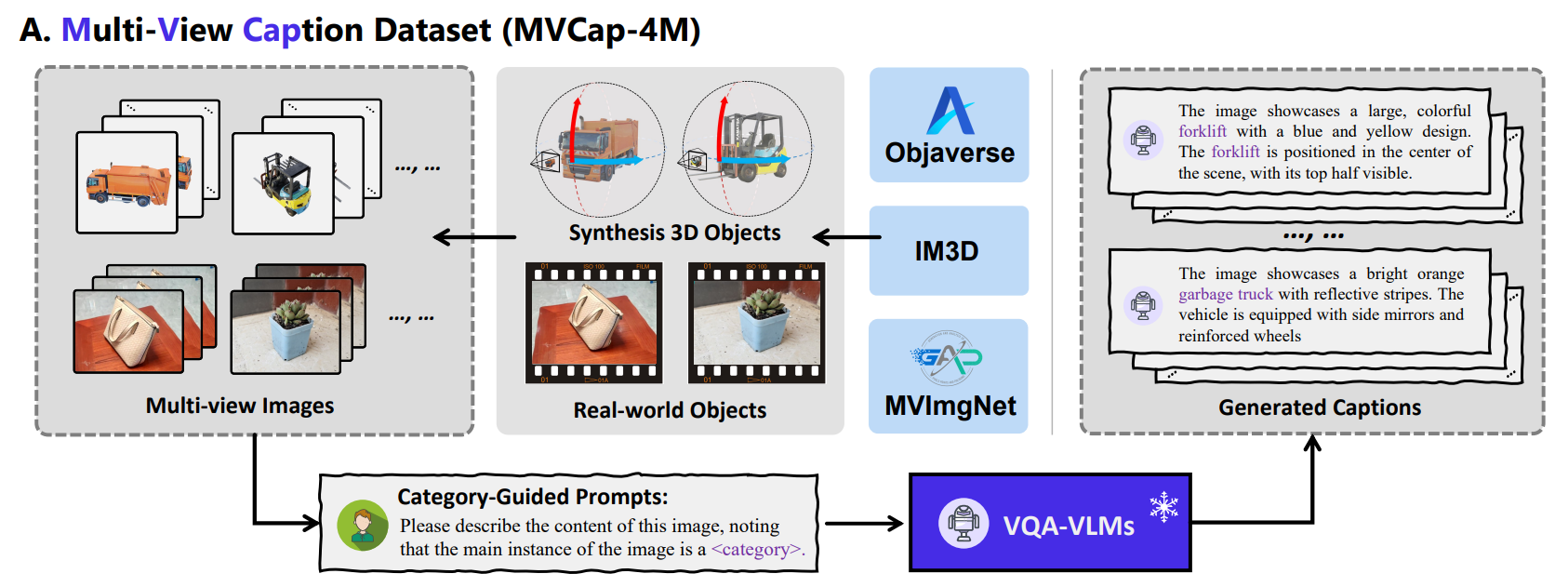
We create the first multi-view image caption dataset by collecting multi-view samples from existing 3D object and video datasets, and generating category-guided descriptions using VLLMs.

Generated multi-view captions with common and category-guided prompts.
We sampled source multi viewpoint images from three existing 3D datasets:
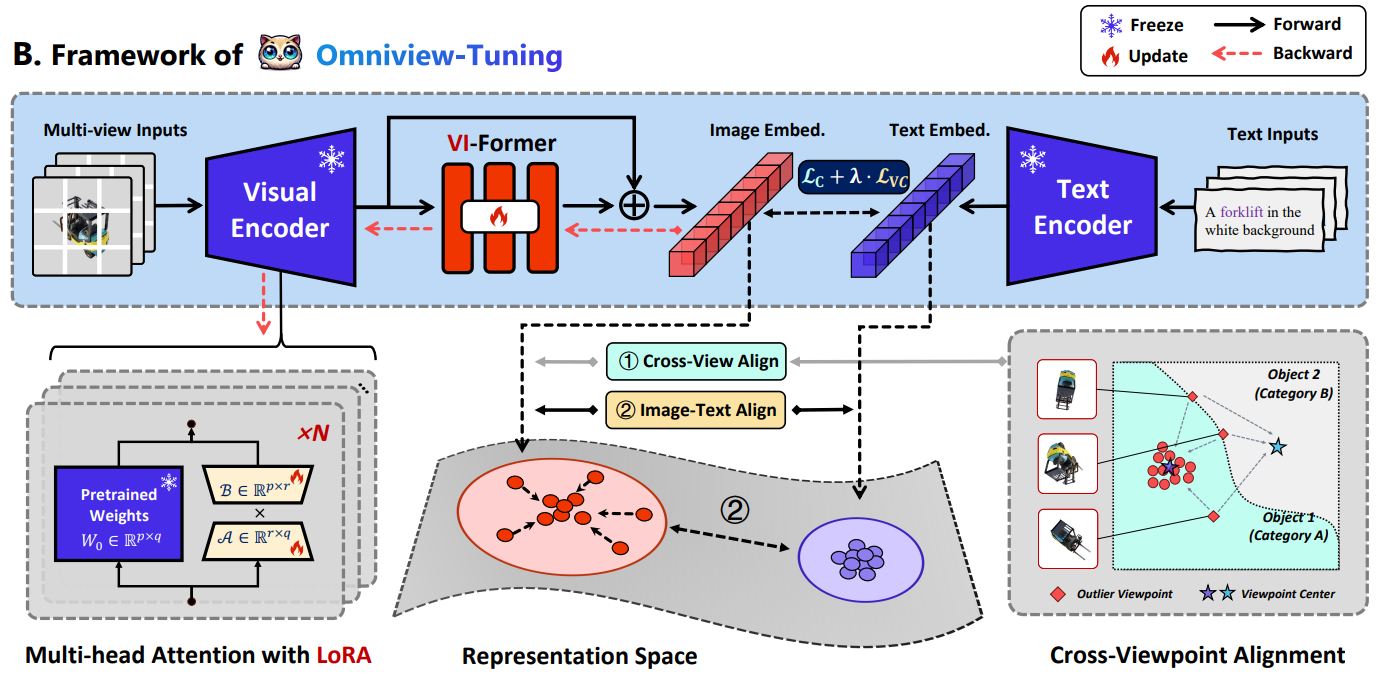
![]() OmniView-Tuning
employs multi-view image-text pairs for training additional learnable components. To amplify the model's proficiency in learning viewpoint-invariant representations, we introduce a Cross-viewpoint Alignment objective, ensuring
that representations of the same object from different viewpoints are close and
unified in the high-dimensional feature space.
OmniView-Tuning
employs multi-view image-text pairs for training additional learnable components. To amplify the model's proficiency in learning viewpoint-invariant representations, we introduce a Cross-viewpoint Alignment objective, ensuring
that representations of the same object from different viewpoints are close and
unified in the high-dimensional feature space.
To prevent performance trade-offs due to the concept drift from aggressive viewpoint alignment, we innovatively construct the optimization paradigm of OVT in a minimax-like form. The optimization process includes identifying extreme outlier viewpoints during the maximization step, while optimizing the model's invariant representation for these outlier samples in the minimization step. This strategy enables the model to focus more on the worst-case viewpoint samples, thereby maximally preserving the original embedding distribution and avoiding performance degradation while saving computational costs. Moreover, OVT is designed in a ParameterEfficient Fine-Tuning manner to improve efficiency, and creatively incorporates two trainable parameter modules: an embedding transformation module named VIFormer and the Low-Rank Adaptation (LoRA) weights, to acquire additional viewpoint invariance capabilities efficiently
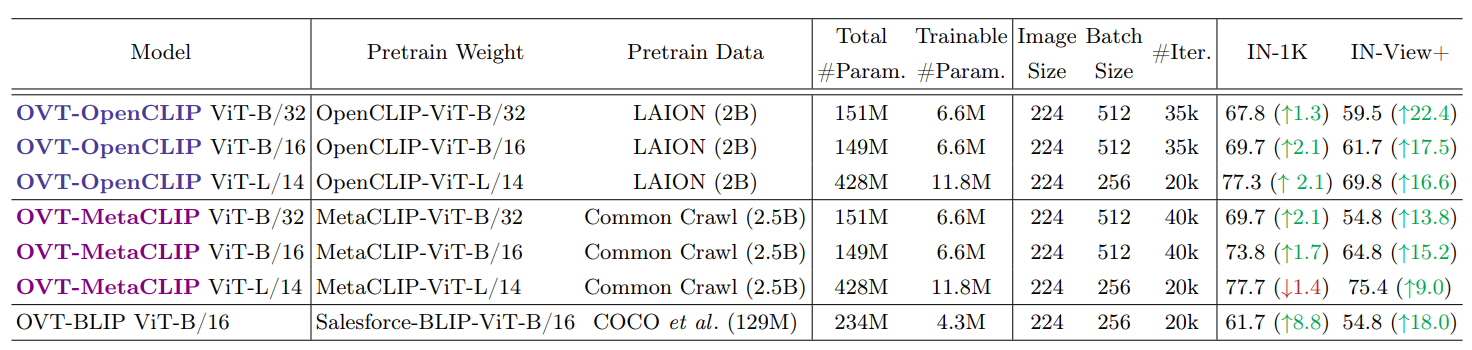
Configurations of OVT and zero-shot Top-1 accuracy (%) on ImageNet-1K with ImageNet-V+.
The number in parentheses shows the performance change relative to the pre-trained weights. Through OVT training, each model maintains the performance on ImageNet-1K (IN-1K) while significantly improving the performance on ImageNet-V+ (IN-V+.), narrowing the performance gap.
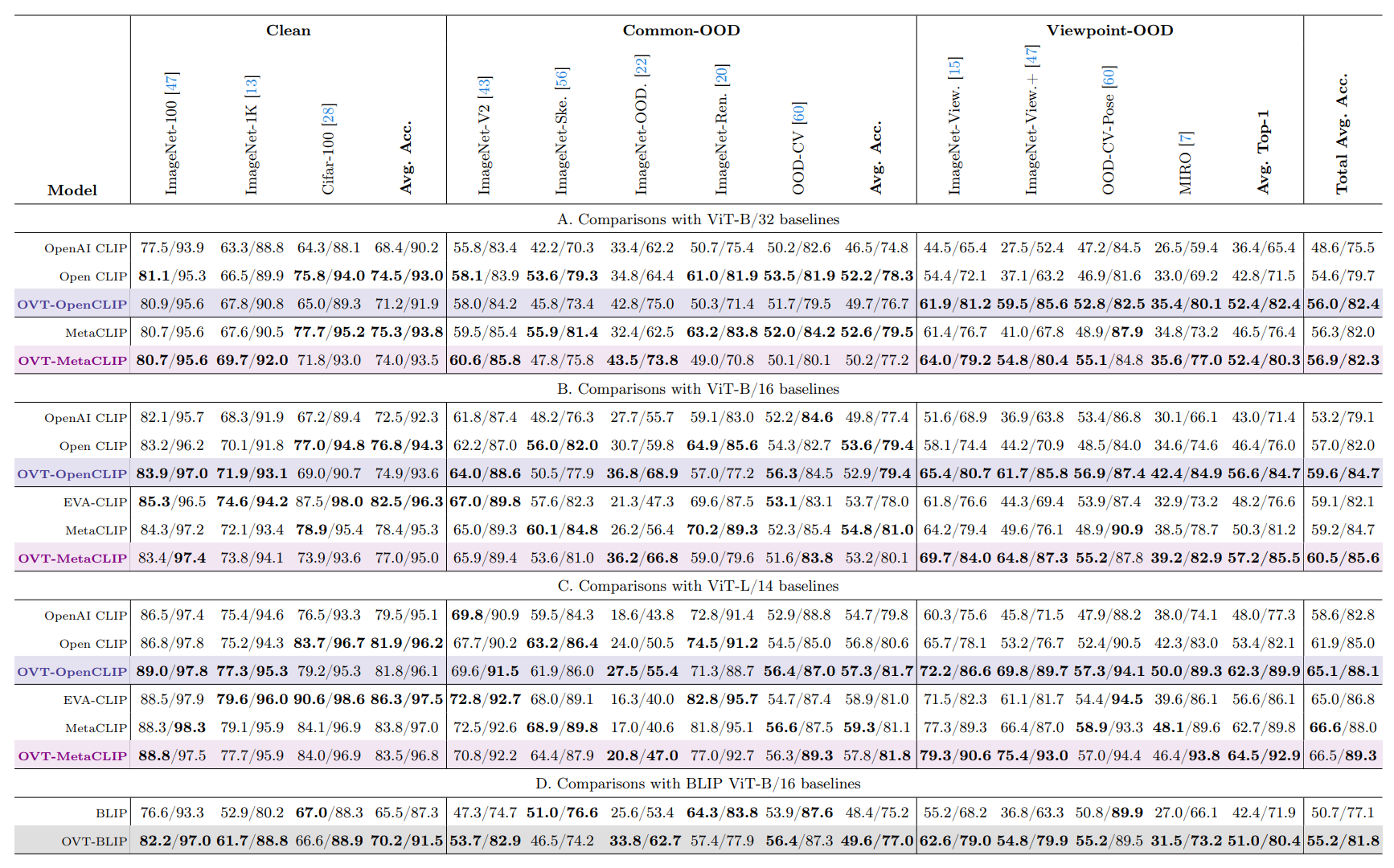
Top-1/Top-5 zero-shot accuracy (%) under different benchmarks.
OVT significantly enhances the models' invariance to Viewpoint-OOD samples. Across different VLP architectures and visual encoders, OVT-trained models perform best on almost all viewpoint-OOD benchmarks. On the average accuracy of viewpoint-OOD datasets, OVT-OpenCLIP with ViT-B/32, ViT-B/16, and ViT-L/14 shows improvements of 9.6%, 10.2%, and 8.9% over OpenCLIP, respectively. OVT-BLIP demonstrated an average improvement of 8.6%.

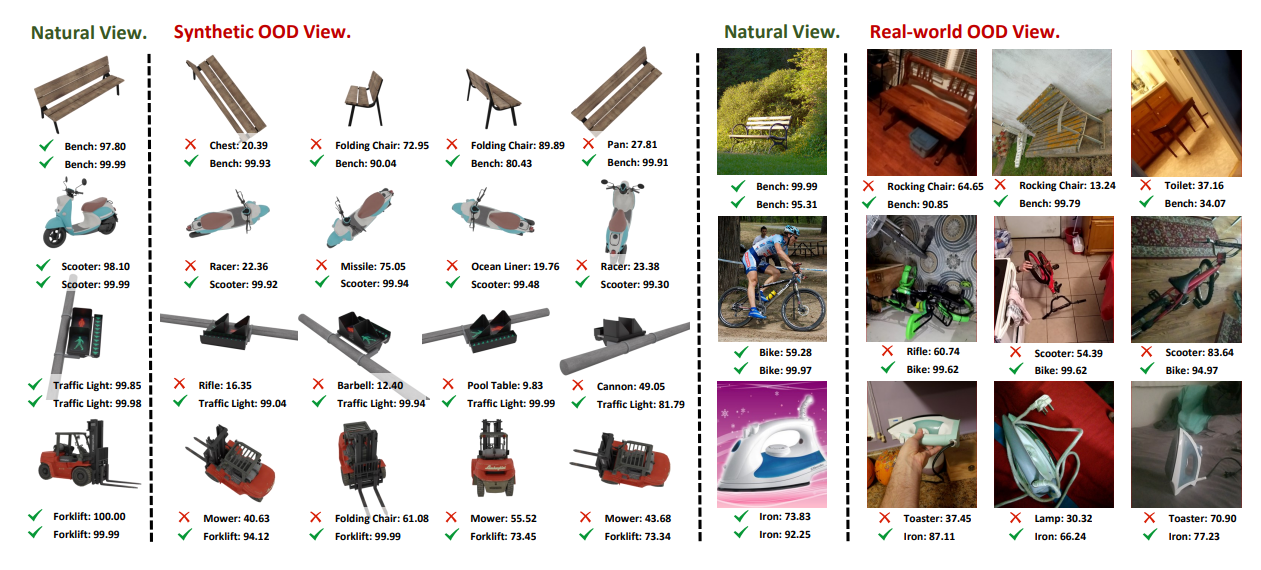
The answers generated by OpenFlamingo-3B using our OVT-CLIP and the original OpenAI CLIP as vision encoder, where red texts indicates incorrect category descriptions, and green texts represents correct.

The image descriptions generated by LLaVa-13B using our OVT-CLIP and the original OpenAI CLIP as vision encoder, where red texts indicates incorrect category descriptions, and green texts represents correct
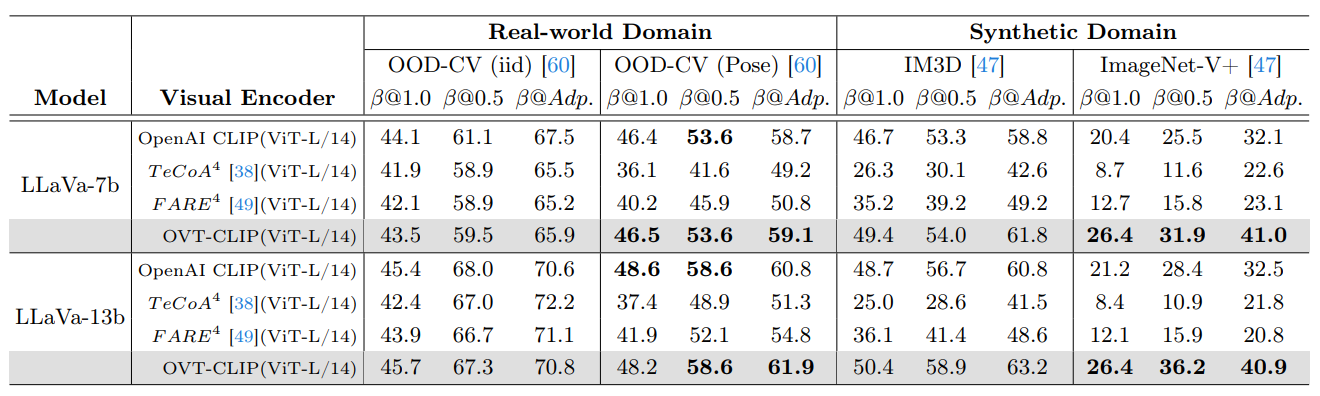
Image captioning performance under clean distribution samples and viewpoint-OOD samples from Real-world and Synthetic domains. We utilize the MPNet to calculate the similarity between generated descriptions and ground-truth labels, considering predictions successful if they exceed the similarity threshold β.
If you find our work useful, please consider citing our paper:
@article{ruan2024omniview,
title={Omniview-Tuning: Boosting Viewpoint Invariance of Vision-Language Pre-training Models},
author={Ruan, Shouwei and Dong, Yinpeng and Liu, Hanqing and Huang, Yao and Su, Hang and Wei, Xingxing},
journal={arXiv preprint arXiv:2404.12139},
year={2024}
}@inproceedings{ruan2023towards,
title={Towards viewpoint-invariant visual recognition via adversarial training},
author={Ruan, Shouwei and Dong, Yinpeng and Su, Hang and Peng, Jianteng and Chen, Ning and Wei, Xingxing},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={4709--4719},
year={2023}
}@article{dong2022viewfool,
title={Viewfool: Evaluating the robustness of visual recognition to adversarial viewpoints},
author={Dong, Yinpeng and Ruan, Shouwei and Su, Hang and Kang, Caixin and Wei, Xingxing and Zhu, Jun},
journal={Advances in Neural Information Processing Systems},
volume={35},
pages={36789--36803},
year={2022}
}